엘라스틱서치 운영 준비 - 아키텍처 구성
이 글은 `당신의 신문, 당신` 프로젝트를 진행하면서 간단한 Elasticsearch 클러스터를 구성하면서 진행된 일련의 과정을 정리해놓은 글입니다. Elasticsearch를 제대로 원활하게 사용하기 위해서는 높은 하드웨어 스펙을 가지고 있어야 하지만 신입 개발자를 준비하는 상태로 높은 스펙을 사용하기에는 경제적 문제가 있어 극한의 환경에서 구성하여 사용하였습니다. Elasticsearch의 구성과 하드웨어 스펙은 다음과 같습니다.
하드웨어 스펙과 구성 아키텍처
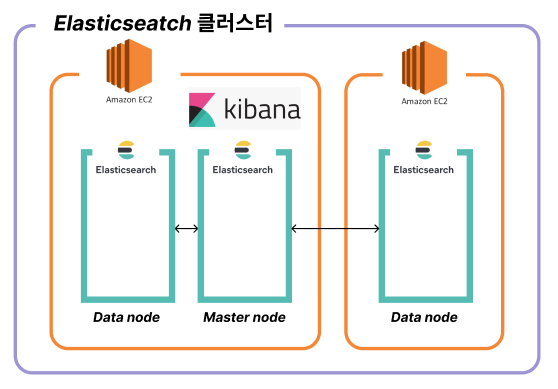
Docker를 이용하여 작은 인스턴스에 3개의 노드를 사용했던 지난 글에서 언급했듯 Elasticsearch를 사용하기 위해서는 하드웨어의 스펙이 어느정도 받쳐주어야 합니다. 그렇기 때문에 어떻게 이런 스펙을 구상하게 되었는지에 대한 이해와 차이점에 대해 이해를 돕기 위한 간략한 설명을 먼저 하겠습니다.
아키텍처의 변화
Docker를 사용하여 3개의 노드 + 1개의 키바나 컨테이너를 올린 상황과 새롭게 구성하는 아키텍처의 다른 점은 다음과 같았습니다.
| 기존 상황(Docker) | 새로운 서버 | |
| 서버 스펙 | GCP : e2.medium Hardware - 1~2 core(공유) - 4gb memory OS - ubuntu 22.04 Elasticsearch version elasticsearch elk stack v7.10.1 구현방식 docker-compose 컨테이너 구성 |
AWS : t3.large Hardware 2 core 8gb memory OS ubuntu 22.04 Elasticsearch version elasticsearch elk stack v7.10.1 구현방식 elasticsearch 자체 설치 |
| 내부 어플리케이션 |
|
|
기존 서버의 한계
기존 서버는 총 4gb 메모리를 빡빡하게 사용하였기 때문에 OS인 ubuntu가 사용할 수 있는 메모리 자체가 적었습니다. Elasticsearch에 아무런 작업이 실행되지 않더라도 jvm을 위하여 OS 자체에 Memory lock 옵션을 걸어두었기에
Elasticsearch와 키바나가 잡고있는 메모리가 80% 였기에 Socket 통신과 검색 작업을 동시에 할 때 병목현상이 보였습니다.

cpu 자체에도 문제가 있다고 판단 되었습니다. GCP에서 사용한 medium size는 1개의 기본 코어를 가지고 버스팅 기능 발동시 추가로 물리적 cpu를 지원받아 사용되는데 medium의 경우 120초를 지원합니다. 다음 사진을 보았을 때 1분 load 율이 3.14 대로 코어 2개로 해결하더라도 부족했기 때문에 시간이 흐름에 따라 로드율이 지속적으로 늘어났습니다.

이 문제는 Bulk Insert 작업에서 빈번한 socket timeout을 불러왔다고 판단되었고, 병목현상을 줄이기 위해 노드 갯수를 줄이고 서버 자체의 스케일업, 스케일 아웃이 필요하다고 생각했습니다.
해결책
- Elasticsearch 공식 문서의 제안에 따라 전체 메모리에서 OS가 최소 50%를 가지고 있을 수 있도록 했습니다.
- 이는 Socket 통신에서의 병목현상에 도움을 줄 수 있을 것으로 판단되었으며 전체적인 부하를 줄이는데 도움이 될 것이라 판단했습니다.
- 노드가 가져갈 수 있는 메모리 양을 늘리기 위해 노드 갯수를 줄이고 서버 자체의 스케일 업을 진행했습니다.
- 각 노드의 역할 분리를 하여 JVM heap 메모리 영역을 세부적으로 커스터 마이징하고 필요한 만큼의 양만큼 최적화하였습니다.
- 마스터 노드는 단순히 코디네이터 노드 역할을 할 수 있도록 분리하였고, 추후 클러스터가 구현이 된다면 각 노드별 쿼리를 보내주고 취합하는 노드로서 사용하기 위해 분리를 하였습니다. 또한, JVM 힙 메모리를 최대한 줄일 수 있을 만큼으로 줄여 같은 서버 내 데이터 노드에 더 할당 할 수 있도록 최적화를 진행했습니다.
- 데이터 노드는 마스터 노드에서 양보한 jvm 힙메모리 만큼 더 가질 수 있도록 설정했습니다.
- 최초 1gb로 주었으나 병목현상이 발견되었고 2gb로 두어 안정화 시켰습니다.
- 검색시 여러 개의 쿼리 연산을 할 수 있도록 코어의 갯수를 늘림으로써 원활한 서비스가 되도록 스케일업했습니다.
정리
이 과정을 거쳐오면서 정작 스케일업을 했지만 타당한 방책이었는지는 확실하지 않았습니다. 또한, Data와 Master 노드를 분리하는 과정에서도 많은 시행착오가 있었고, 시간은 물흐르듯 빠르게 흘러갔었습니다. 처음 구성해보는 아키텍처였고, Linux 운영체제에 대한 이해도가 높지 않았었기 때문에 어려웠던 것 같습니다.
타당한 진단과 올바른 해결책을 이행했는지 확인하기 위해서는 Bulk Insert 테스트를 진행하며 확인해보려고 노력했습니다. 그렇기에 저는 다음의 정보를 테스트를 통해 얻고 싶었습니다.
얻고 싶은 데이터
- master node의 jvm 힙 영역이 크지 않아도 무리 없는지
- Bulk 데이터로 밀어 넣을 때 data node 1gb로 충분한지
- 코어가 작게 나마 스케일업이 효과가 있는지
- 안정적인 데이터 bulk 입력이 가능하며 그와 동시에 안정성이 충분한지 + load avg가 0.7 이하로 병목현상이 일어나지 않는지.
다음 글에서는 이 과정이 옳았었는지 확인해보는 테스트에 대해서 작성해보겠습니다.
'Infra > Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] 엘라스틱서치 설치 (0) | 2022.10.12 |
|---|---|
| [Elasticsearch] Ubuntu, Docker-compose를 이용한 Elasticsearch 환경 구성 (0) | 2022.10.12 |
| [Elasticsearch] 엘라스틱서치의 기본 (0) | 2022.10.11 |
| [Elasticsearch] 엘라스틱서치의 역사 (0) | 2022.10.10 |