모든 것이 HTTP

HTTP : HyperText Transfer Protocol
HTTP는 하이퍼텍스트(문서간의 링크)를 통해 이동하는 html을 전송하는 프로토콜로 시작을 했다. 하지만, 현재는 이미지, 영상, 음성 등 모든 형태의 데이터를 HTTP로 전송이 가능하다.
- HTML, TEXT
- IMAGE, 음성, 영상, 파일
- JSON, XML (API)
- 거의 모든 형태의 데이터!
심지어는 서버간의 데이터를 주고 받을 때도 HTTP를 사용한다.
HTTP 역사
- HTTP/0.9 1991년: GET 메서드만 지원, HTTP 헤더 X
- HTTP/1.0 1996년: 메서드, 헤더 추가
- HTTP/1.1 1997년: 가장 많이 사용, 우리에게 가장 중요한 버전
- RFC2068 (1997) -> RFC2616 (1999) -> RFC7230-7235 (2014)
- HTTP/2 2015년: 성능개선
- HTTP/3 진행중: TCP 대신에 UDP 사용, 성능 개선
1.1 자체가 만들어질 때 현재 사용하는 대부분의 기능이 들어가있고, 2와 3의 경우에는 거진 성능개선에 초점이 맞춰져 있으므로 우리에게는 1.1 버전이 중요하다. 1.1 버전도 여러 번의 개정이 되었는데 기술 스펙의 현재 50퍼센트 정도는 RFC2616을 따르고 있으나 우리는 2014년에 개정된 RFC7230-7235를 읽어야 한다. 현업의 기술 스펙은 매번 개선되는 스펙을 따라갈 수 없기 때문이므로 우리는 더 개선된 버전을 읽고 익혀야 한다.
기반 프로토콜
- TCP: HTTP/1.1, HTTP/2
- UDP: HTTP/3
위와 같이 현재는 HTTP/1.1을 주로 사용하고 있고, 2,3도 증가하는 추세이다. 3는 UDP를 기본으로 동작하는데 3에서 안정적인 TCP를 제쳐두고 UDP를 사용하는 이유는 TCP가 안정적이지만 3 way handshake 등 기본적으로 많은 데이터를 가지고 있는 TCP 통신은 메커니즘 자체로 속도가 UDP에 비해 느리기 때문이다. 이 문제를 해결하기 위해서 UDP 프로토콜을 사용하고 어플리케이션 단에서 성능을 최적화하여 새로운 설계를 해 나온 것이 HTTP/3 버전이다. 2와 3은 1.1의 성능 개선 버전이라 보면 되기 때문에 우리는 1.1만 제대로 알아두면 지장없는 개발이 가능하다.
실제 구글과 네이버에서는 어떤 버전을 사용하고 있을까?
| 구글 `이동욱` 검색 | 네이버 홈 화면 이동 |
 |
 |
개발자 도구를 통해 확인해보면 대부분 h3, 즉 HTTP/3 버전을 사용하고 있다. 한국의 네이버는 http/1.1, h2를 사용하여 통신하는 것을 확인할 수 있다.
HTTP 특징
- 클라이언트-서버 구조
- 무상태 프로토콜(stateless), 비연결성
- HTTP 메시지
- 단순함, 확장가능
클라이언트-서버 구조

HTTP를 사용하여 통신을 할 때는 Request와 Response 구조를 사용하여 통신하게 된다. 클라이언트는 서버에 요청을 내고, 서버로부터 응답을 대기한다. 서버는 들어온 요청을 토대로 결과를 만들어서 응답을 하게 된다.
이렇게 클라이언트와 서버를 구분하여 통신을 이해함으로써 오는 이점은 다음과 같다. 비즈니스 로직과 데이터는 서버에 모두 밀어넣으면서 반대로 클라이언트에서는 UI와 사용성에 집중하므로써 클라이언트와 서버가 독자적으로 고도하게 진화할 수 있다. 과거의 웹 기술을 아는 대로 이야기 해보자면 예를들어 JSP와 같은 서버렌더링 템플릿 엔진에서도 JAVA 로직을 짤 수 있는데 이렇게 로직을 프론트에 두는 것이 아니라 뷰단에서는 단순히 UI를 그리는 작업만 하고 관련 비즈니스 로직은 컨트롤러, 서비스단으로 모는 것이 MVC의 핵심이다.(물론 JSP는 서버에서 렌더링을 하는 것이다. ) 이처럼 개념적으로 클라이언트와 서버를 분리함으로써 독자적으로 진화할 수 있는 환경을 구성해준다. 다른 예시로는 서비스가 너무 잘되어 트래픽이 폭주하는 환경에서도 클라이언트와 서버를 분리하게 되면 서버의 개선만 하면 되기 때문에 유지보수 입장에서도 수월하게 진행할 수 있다.
무상태 프로토콜 - Statelass VS Stateful

stateless란?
서버가 클라이언트의 상태를 보존하지 않는 것을 말한다. stateless하게 구성할 경우 서버의 확장성이 높아 스케일 아웃하기가 좋다. 클라이언트의 상태를 확인하지 않기 때문에 자원을 공유할 필요없기 때문이다. 이와 반대로 단점은 클라이언트가 추가 데이터를 전송해야만 한다. 이 말은 만약 어떤 한 서비스를 이용하려면 그 서비스에 필요한 모든 정보를 가지고 있어야지만 추가적인 통신 없이 서비스 처리가 가능하다는 뜻이다.
이 개념과 반대의 개념이 Stateful이라는 개념이다. 서버가 클라이언트의 상태를 모두 기억해두기 때문에 서버에는 부하가 생기게 된다. 또한, 한번 통신한 서버가 정보를 가지고 있기 때문에 다음 통신에 효율을 높이기 위해 다시 통신한 서버와 통신을 해야한다. 이렇게 되면 특정 서버에만 트래픽이 몰릴 가능성이 있어 트래픽 분산에 불리하다. 설령 정보를 모든 서버가 공유하더라도 결국 공유에 대한 자원 소모가 필요하게 된다.(세션 스토리지 같은 예가 있을 것이다.) 그리고 만약 서버의 장애가 날 경우에 장애난 서버와 통신을 하던 클라이언트는 기존까지의 통신 과정을 다른 서버와 반복을 해야할 것이다.
Stateless가 가지는 실무적 한계
Stateless로 설계된 서비스의 장점이 아주 좋아보인다. 하지만, 실제 실무에서는 모든 것을 무상태로 설계할 수 없을 수가 있다. 단순히 로그인이 필요없는 단순한 서비스 소개 화면이라면 무상태로 서비스를 하는 것에 큰 어려움이 없을 것이다. 하지만 로그인과 같이 인증, 인가 문제만 하더라도 클라이언트의 상태를 유지해야만 서비스를 할 수 있다. 이런 경우에는 브라우저의 쿠키와 서버 세션 등을 사용해서 상태를 유지하며 상태 유지는 최소한으로 사용하는 것이 좋다.
비 연결성(connectionless)
클라이언트-서버 간의 통신에서 TCP/IP 통신은 연결을 유지한 상태로 통신이 된다면 1:1로서 연결이 되며 자원을 사용할 것이다. 만약 1000명의 클라이언트가 동시에 서버에 연결을 한다면 어떻게 될까? 1000대는 각자 필요할 때 요청을 보내겠지만 서버에서는 클라이언트에서 오는 요청을 받기 위해 1000개의 연결을 유지해야할 것이다. 이렇게 연결을 유지하는 것만으로도 다대일의 일을 해야하는 서버는 소모해야하는 자원이 크다.
이와달리 연결을 유지하지 않아도 되는 구조라면 어떨까? 간단하게도 1000명이 요청을 하더라도 응답을 하자마자 연결을 끊어버리게 되면 연결의 idle 상태로 유지되는 자원 소모가 줄어들게 되면서 더 효율적인 자원 사용이 가능할 것이다. 이런 개념이 비 연결성이라는 개념이다.
웹에서 사용하는 HTTP는 기본적으로 연결을 유지하지 않는 모델이다. 대부분의 요청이 초 단위 이하의 빠른 속도로 응답을 하게 된다. 그렇기 때문에 1시간 동안 수천명이 서비스를 사용하더라도 실제 서버에서 동시에 처리하는 요청은 수 십개 이하로 작게 된다. 웹 통신은 부하테스트처럼 지속적인 부하를 일으키지 않기 때문에 서버 자원을 매우 효율적으로 사용할 수 있다.
비 연결성의 한계와 극복

하지만, 이런 비 연결성의 장점이 단점으로 바뀌는 순간은 바로 TCP/IP 연결을 매번 새로 연결해야 하는 순간이다. 이말인 즉슨 TCP 3 way handshake 시간이 추가된다는 말이고 이는 효율적이지가 않다. 구글에서 `이동욱`만 검색해보더라도 이동욱의 사진과 그의 정보들이 나오게 되는데 이 수 많은 정보들을 받을 때마다 연결을 끊고 연결하는 것은 상당히 비효율적이다.

그런데 현재는 이런 걱정을 할 필요가 없다. 지금은 HTTP 지속 연결(Persistent Connections)로 문제를 해결한 상태이며 HTTP/2와 HTTP/3로 발전하면서 성능개선이 상당히 많이 되었다.
우리가 Stateless를 기억해야 하는 이유는 실제 실무에서 같은 시간대에 맞추어 발생하는 대용량의 트래픽을 해결할 때 유용하기 때문이다. 우아한 형제들의 배달의 민족 서비스 마이크로서비스 아키텍처 여행기에서도 나오는 이야기처럼 치킨 이벤트로 인한 동 시간대의 수 많은 트래픽을 대처하기 위해서는 클라이언트들의 상태를 기억할 필요없는 무상태라는 특징을 활용해야하기 때문이다. 이런 특수한 상황을 위해 개발자는 최대한 머리를 짜내어 Stateless한 개발을 해야한다.
HTTP 메세지
HTTP는 요청과 응답 메세지로 나뉘게 됩니다. 두 메세지는 특정 구조를 가지게 되는데 다음 그림과 같습니다.
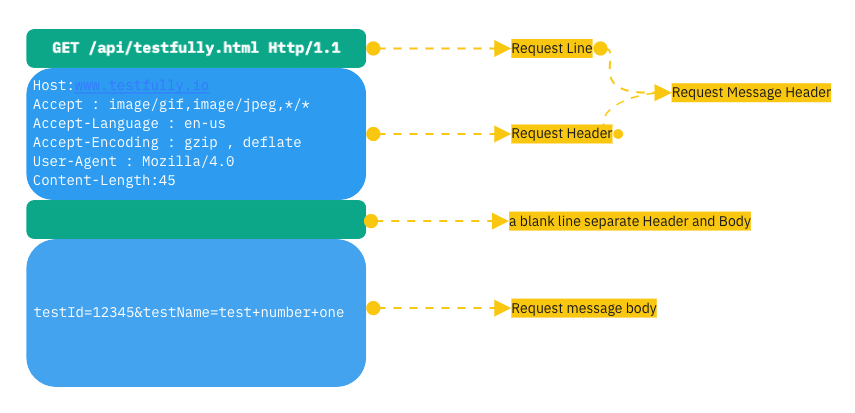 |
start-line 시작라인 |
| header 헤더 (여러개) | |
| empty line 공백 라인 (CRLF) 반드시 존재 | |
| message body(요청도 가질 수 있음) |
시작라인
- 요청 메시지: start-line = request-line
- HTTP 메서드
- 종류 : GET, POST, PUT, DELETE...
- 요청 대상 (/search?q=이동욱)
- 절대경로(`/`)로 시작(다른 방법도 있긴함.)
- HTTP Version
- HTTP 메서드
- 응답 메시지: start-line = status-line
- HTTP Version
- HTTP 상태 코드: 요청 성공, 실패를 나타냄
- 200: 성공
- 400: 클라이언트 요청 오류
- 500: 서버 내부 오류
- 이유 문구: 사람이 이해할 수 있는 짧은 상태 코드 설명 글 포함
HTTP 헤더
header-field( = field-name):OWS(띄어쓰기 허용) field-value
헤더는 위와같은 형태로 작성되게 된다. 예를 보면 다음과 같다.
- Host: www.google.com
- Content-Type: text/html;charset=UTF-8
헤더는 HTTP 전송에 필요한 모든 부가정보를 담는 역할을 한다. 메시지 바디의 내용, 메시지 바디의 크기, 압축, 인증, 요청 클라이언트(브라우저) 정보, 서버 어플리케이션 정보, 캐시 관리 정보 등 다양한 정보를 담아 두고 통신을 한다. 표준 헤더는 엄청나게 많으며 필요시 임의의 헤더를 추가하여 사용 가능하다. 예를 들어 Spring Security에서 filter에서의 exception 핸들링을 하고 싶다면 header에 임의의 헤더를 추가하여 메타 데이터를 담아두고 인가가 실패한 경우 Entrypoint에서 header의 값을 읽어와 다양한 exception 핸들링을 할 수도 있다.
HTTP 메시지 바디
메시지 바디에는 실제 전송될 데이터가 담긴다. 옛날에는 HTML 문서가 담겼지만 현재는 모든 데이터, 이미지, 영상, JSON 등 byte로 표현할 수 있는 데이터를 담을 수 있다.
정리
HTTP는 단순하며 확장 가능하다는 특징이 있다. 표준 기술로서 성공하게 된 계기로는 단순하며 확장 가능하기 때문일 것이다.
HTTP는 모든 데이터를 전송하며 서버 클라이언트 구조를 가진다는 점, 무상태 프로토콜로서 확장성에 강한 이점을 가진다는 점을 대표적으로 기억해두면 좋을 것 같다.
'노트 정리 > 모든 개발자를 위한 HTTP 웹' 카테고리의 다른 글
| [HTTP 웹] 6. HTTP 상태 코드 (0) | 2022.10.29 |
|---|---|
| [HTTP 웹] 5. HTTP 메서드 활용 (0) | 2022.10.28 |
| [HTTP 웹] 4. HTTP 메서드 (0) | 2022.10.27 |
| [HTTP 웹] 2. URI와 웹 브라우저 요청 흐름 (0) | 2022.10.25 |
| [HTTP 웹] 1. 인터넷 네트워크 (0) | 2022.10.24 |